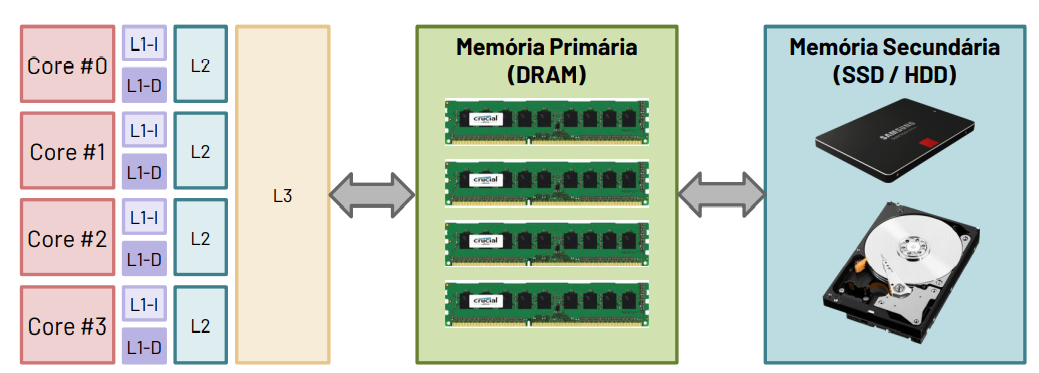
# Hierarquia de memória - Memórias Cache
Caches: A safe place to store things that we need to examine Representa o nível na hierarquia de memória entre o processador e a memória principal.

Como as caches L1 têm uma dimensão reduzida, geralmente os sistemas contêm uma hierarquia com 2 a 3 níveis de cache. A cache L1 é a de menor dimensão, portanto mais próxima do processador.
# Principio de funcionamento
Quando o processador precisa de um dado, faz o pedido à cache:
- Se os dados estiverem na cache, devolve-os imediatamente:

- Se os dados não estiverem na cache, faz o pedido à memória:
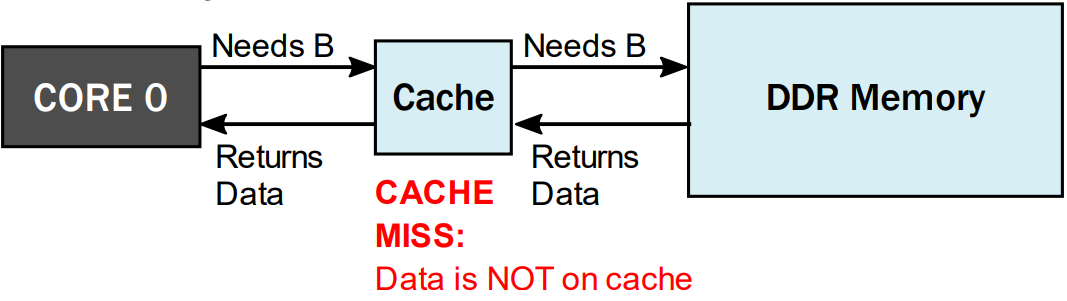
Quanto maiores e mais distantes estiverem as caches, maior a latência de acesso.
# Principio da Localidade
Localidade Temporal: Se acedermos a um endereço A, é provável que num futuro próximo necessitemos de o aceder novamente. Quando acedemos ao dado/instrução no endereço A, já que temos de pagar o custo de o ir buscar à memória RAM, mas vale armazená-lo em memória cache.
Localidade Espacial: Se acedermos a um endereço A, é provável que num futuro próximo necessitemos de aceder aos endereços adjacentes a A. Quando acedemos ao dado/instrução no endereço A, já que temos de pagar o custo de o ir buscar à memória RAM, mais vale trazer também alguns dados/instruções contíguas.
Regra 90/10: Um programa passa 90% do tempo a executar 10% das instruções.
# Organização das memórias caches
A cache mapeia os endereços da memória RAM num conjunto limitado de entradas. O que faz com que múltiplas entradas da memória RAM correspondem à mesma entrada da cache. Assim, para conseguirmos guardar na cache os dados precisamos de:
Bloco de dados: Sequência de palavras de dados, correspondentes a endereços consecutivos em memória.
TAG: Etiqueta para confirmação do endereço.
V: Campo binário para identificar se a entrada é válida (V = 1) ou inválida (V = 0).
CTRL: Sinais de controlo auxiliares.
Casos particulares
Caches de mapeamento direto: Apenas uma via, com múltiplas entradas.
Cache associativa: N vias, cada uma com múltiplas linhas. A organização de cada uma das N vias é idêntica.
Cache completamente associativa: Multiplas vias, mas cada uma contendo apenas uma linha.
Quando o processador precisa de um dado, faz o pedido à cache L1. De acordo com a cache L1, esta decompõe a palavra de endereço em:
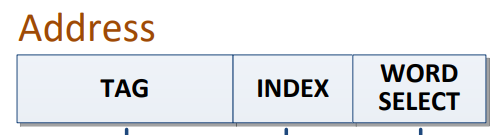
- Escolher a entrada/linha da(s) tabela(s): INDEX
Verificar se a entrada é válida, ou seja, V=1.
Verificar se a entrada corresponde ao endereço pedido, confirmar o valor da TAG.
- Se 2 e 3 forem verdadeiros HIT. Ler a palavra pedida a partir da cache, sendo o primeiro byte associado pelo valor do offset.
Nota
Por omissão, o campo de endereço geralmente tem a mesma dimensão que a largura do registo fisico. Por exemplo: O RV32G tem endereços de 32 bits.
Por exemplo:
Cache L1 para um processador com ISA RV32G
Caracteristicas da memória cache:
- Mapeamento Direto
- Capacidade para 23 KB
- Linhas com 32B
Address = 32 bits
Como uma linha tem 32B o que corresponde a 32 endereços então:
Index:
Logo
# Estatisticas de acesso à cache
Por exemplo:
Desculpa, ainda não esta aqui nada 😃
# Caches de mapeamento associativo
Maior associatividade Menor número de conflitos na cache.
Contudo, o aumento do número de vias geralmente leva a:
- Maior tempo de acesso.
- Mais recursos de hardware.
- Maior área de silicio e maior consumos de potência.
Geralmente as caches têm um número de vias limitado
# Políticas de substituição
Em caso de MISS, qual das vias deve ser escolhida?
Se a linha selecionada estiver livre (V = 0) em pelo menos uma via escolhemos essa via.
- First in First out: Substituir o bloco que está na cache à mais tempo
- Least Recently Used: Substituir o bloco que está à mais tempo sem ser acedido.
- Random replacemeant: Escolher uma via ao acesso.
- Pseudo-Least Recently used: Não substituir o bloco que foi acedido à mais tempo.
# Escrita de dados: Política de escrita e de alocação
Políticas de escrita:
- Write-back: Escrita é realizada na cache.
Na sequência de um MISS na cache, a linha modificada anteriormente é substituida por outra linha. Para garantir a coerência é necessário escrever o valor na memória antes de alterar a linha. Contudo é necessário que o controlador da cache tenha informação relativamente às linhas modificadas.
SOLUÇÃO: Introduzir um bit de controlo adicional, Dirty bit (D), indica quais as linhas modificadas. Quando D = 1, indica quais as linhas que devem ser escritas em memória antes de serem substituidas.
- Write-through: A escrita não é realizada na cache. Não necessita do Dirty-bit, visto que aqui a memória já foi atualizada.
Para reduzir a latência das escritas, é habitual o uso de um write - buffer:

Políticas de alocação:
Write alocate: Uma escrita obriga à alocação dos dados na cache.
Write not - alocate: Uma escrita nunca leva à alocação dos dados na cache.